Even the most robustly architected systems fail from time to time. Fortunately, there are steps you can take to limit your downtime exposure. Here are five automated strategies to help you implement high availability:
1. Application-Level Routing
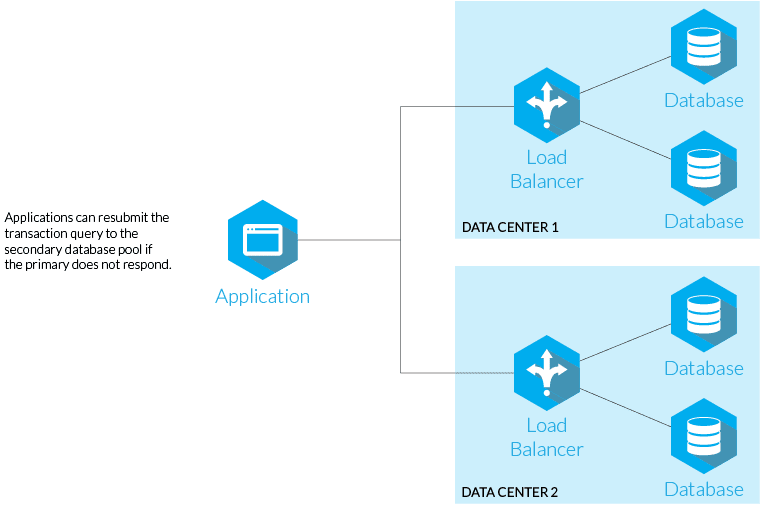
In the event of a transaction failure, cloud-aware applications can be engineered to intelligently route transactions to a secondary service point. A failed transaction query is automatically reprocessed at the secondary working location.
2. Network IP Management
Network IP Management allows a published service IP to move between machines at the time of a failure. This is classified as a self-healing process, where two servers monitor one another. If the first server malfunctions, the second server assumes its roles and processes.

Some packages for Linux that provide this functionality are keepalived and the Linux-HA suite.
3. Monitoring
A well-integrated monitoring package not only provides insight into an application and its current function, it monitors error-rates that exceed a predefined threshold. For example, an e-commerce site can set up monitoring on a payment gateway so that if credit card authorization transactions exceed a 20% failure rate, their Network Operations Center (NOC) automatically gets an alert and self-healing tasks on the infrastructure initiate.
Some widely available monitoring packages are Nagios, Cacti, Zabbix, and Icinga.
4. Stateless Transactions
Engineering an application to perform transactions in a stateless manner significantly improves availability. In a stateless model, any machine only keeps state (data on) transactions that are ‘in fly,’ but after a transaction is completed, any machines that die or degrade have no effect on the state or memory of historic transactions. Clients are therefore not limited to server dependence, and the loss of any pool member in a tier ensures the client session is not interrupted due to a hardware or application fault on a discrete pool member.
Amazon.com leverages stateless transactions with a static key-value store to save shopping carts indefinitely.
The key is to avoid storing permanent state (i.e., transactions, inventory, user data) on individual logical or physical servers.
5. Multi-Site Configurations
In the (unlikely) event of a catastrophic hardware failure, resources can be redeployed to a secondary location in minutes and with little planning. Data replication and resource availability is present in the secondary location, and the just-in-time deployment of entire application infrastructures is measured in minutes, not hours or longer.
When architected and implemented properly, multi-site configurations allow a company to redeploy their entire infrastructure in a new data center.
An organization that cannot tolerate downtime in their application infrastructure will benefit the most from a multi-site configuration. In this situation, the additional site would be a completely independent data center that hosts an independent copy of the primary site infrastructure. Depending on how the site application is configured, the additional site can either be in an active-active configuration that services a portion of the traffic coming into the site, or a primary-failover site that will not serve traffic, but sits idle while continuously replicating data from the primary.
